By Theofilos Ioannidis (tioannid [at] di [dot] uoa [dot] gr), created on , last updated on
In this section, we provide instructions to the user in order to run an experiment with the RDF4J module against the smallest version of the Scalability workload which is part of the Geographica 2[1] benchmark. For this example, we used the first installation method of GeoRDFBench Framework with pre-built binaries at the /data/geordfbench path.
GeoRDFBench Framework comes prebundled with JSON specifications of all Geographica 2 GeoSPARQL and LUBM(1, 0) SPARQL benchmark components, such as datasets, querysets, execution model, etc. Apart from the detailed representation of a benchmark components where each one is independent from the other, GeoRDFBench offers a more compact representation, as a single workload JSON specification file. This specification combines the specifications of dataset, queryset and execution. The Scalability workload of Geographica 2 features a queryset of 3 GeoSPARQL queries against a selection of 6 datasets of increasingly bigger size: 10K, 100K, 1M, 10M, 100M, 500M triples. The scalability 10K workload compact specification is located in:
/data/geordfbench$ tree -L 1 json_defs/workloads/
json_defs/workloads/
├── censusmacrogeocodingWLoriginal.json
├── LUBM_1_0_WL_GOLD_STANDARD.json
├── querysets
├── rwmacrocomputestatisticsWLoriginal.json
├── rwmacromapsearchWLoriginal.json
├── rwmacrorapidmappingWLoriginal.json
├── rwmacroreversegeocodingWLoriginal.json
├── rwmicroWLoriginal.json
├── scalabilityFunc100K_WLoriginal.json
├── scalabilityFunc100M_WLoriginal.json
├── scalabilityFunc10K_WLoriginal_GOLD_STANDARD.json
├── scalabilityFunc10K_WLoriginal.json
├── scalabilityFunc10M_WLoriginal.json
├── scalabilityFunc1M_WLoriginal.json
├── scalabilityFunc500M_WLoriginal.json
├── scalabilityPred100K_WLoriginal.json
├── scalabilityPred100M_WLoriginal.json
├── scalabilityPred10K_WLoriginal.json
├── scalabilityPred10M_WLoriginal.json
├── scalabilityPred1M_WLoriginal.json
├── scalabilityPred500M_WLoriginal.json
└── syntheticWLoriginal.json
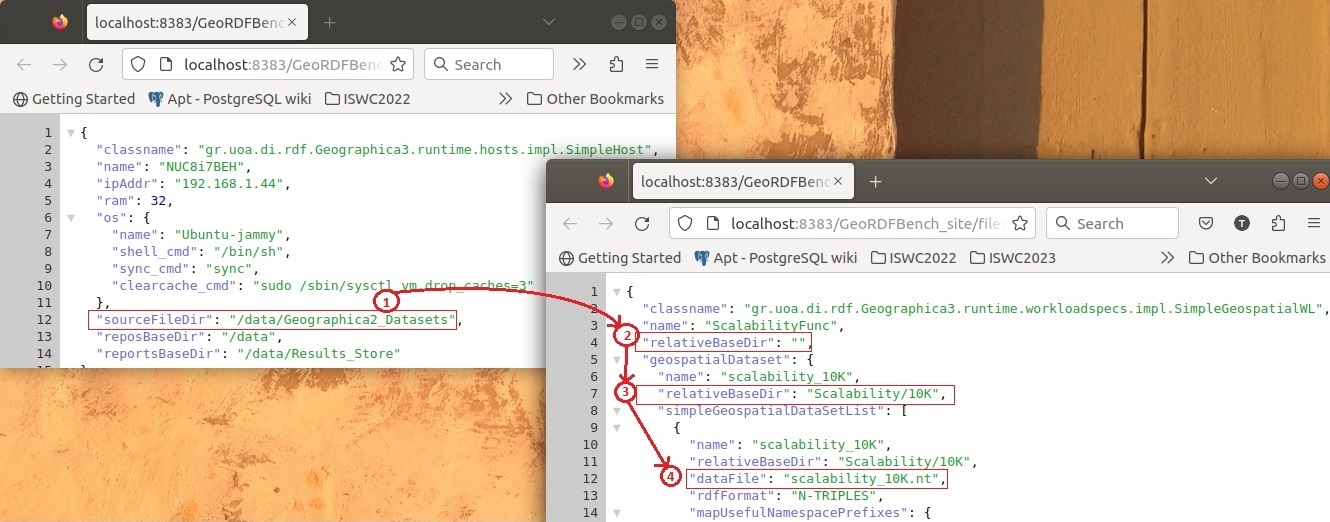
Below (see Figure 1) we can see how path properties from the host and workload specification are combined internally in order to point to the actual N-Triple file /data/Geographica2_Datasets/Scalability/10K/scalability_10K.nt:
The above method allows the same workload specification to run against a different host as long as the dataset file(s) are located in the new host's "sourceFileDir".
/data$ tree -L 1 Geographica2_Datasets/
Geographica2_Datasets/
├── Census
├── PregenSynthetic
├── RealWorldWorkload
├── SyntheticWorkload
└── Scalability
├── 10K
│ └── scalability_10K.nt
├── scalability500MRefDS.nt.gz
└── scalabilityDSGen.sh
The Scalability dataset comprises the scalability500MRefDS.nt.gz reference 500M triples compressed dataset and an accompanying script scalabilityDSGen.sh which helps generate all uncompressed scalability datasets: 10K, 100K, 1M, 10M, 100M, 500M. In the previous listing the 10K uncompressed dataset has been generated already and can be used in our tests. The generation of the uncompressed datasets is handled automatically by the repository generation scripts of the RDF modules. The first time any system creates a repository for scalability 10K workload or dataset, the repository creation script will invoke the scalabilityDSGen.sh script to extract the Scalability/10K/scalability_10K.nt dataset file. All other executions of repository creation scripts by any other system will skip this extraction step. In any case, even its manual use is simple. Assuming that the 10K/scalability_10K.nt did not exist, but we had the reference dataset and script in place, we could issue the following:
/data/Geographica2_Datasets/Scalability$ mkdir 10K; ./scalabilityDSGen.sh scalability500MRefDS.nt.gz 10K > 10K/scalability_10K.ntThe reason we use a compressed reference file and a script to extract chunks of this dataset is twofold: (i) it is network friendly, as it is much easier to download and (ii) it is storage friendly, as uncompressing data is delayed until they are actually needed. The uncompressed reference 500M triple dataset is approximately 95GB, while the compressed version approximate 7GB.
The execution specification of a workload describes the manner that the experiment should be conducted. It specifies how many times a query should be executed and whether it should be with cold or warm caches. It specifies a timeout for each query execution, the timeout for clearing caches between executions and a total timeout for the entire experiment. It defines a policy for the action to take when a query times out. The user can also define the aggregate function to use for custom statistics. It can also be used to print the ground queryset instead of running the experiment. The contents of the Scalability Execution specification is listed below, annotated with explanatory comments:
/data/geordfbench$ cat json_defs/executionspecs/scalabilityESoriginal.json
{
"classname" : "gr.uoa.di.rdf.Geographica3.runtime.executionspecs.impl.SimpleES",
"execTypeReps" : { # each query is executed 7 times = 3 + (1+3)
"COLD" : 3, # 3 recorded times with cold caches
"WARM" : 3 # 1 unrecorded with cold caches and 3 recorded times with warm caches
},
"maxDurationSecsPerQueryRep" : 86400, # max exec time for a query is 24 hours
"maxDurationSecs" : 604800, # max experiment exec time is 7*24 hours
"action" : "RUN", # run the experiment
"avgFunc" : "QUERY_MEDIAN", # use median instead of arithmetic mean
"onColdFailure" : "SKIP_REMAINING_ALL_QUERY_EXECUTIONS", # if a cold execution times out, skip all other executions for this query
"clearCacheDelaymSecs" : 5000 # wait for 5 secs between query executions, when caches need to be cleared
Max query timeout is high because most systems tested in [1] cannot complete the queries against the largest 500M triple dataset. The timeout for clearing caches is required to be several seconds, since some RDF stores need to restart their application and/or database server components to achieve "clear caches". Each query will get executed 7 times in total (if no timeout occurs!), but in the following manner: (i) COLD RUNS: each query executes and records 3 consecutive times, clearing caches before each execution, (ii) WARM RUNS: each query executes 1 time, clearing caches before this execution, followed by 3 consecutive recorded executions without clearing caches, (iii) if during the COLD runs a query times out, it is blocked from executing any other COLD or WARM runs for this query.
In order to reduce the number of arguments required for running a system's repository creation script, it is convenient, but not obligatory, to source the following provided bash script and review how the environment is setup:
tioannid@NUC8i7BEH:/data$ cd geordfbench/scripts/
tioannid@NUC8i7BEH:/data/geordfbench/scripts$ source prepareRunEnvironment.sh nuc8i7beh RDF4JSUT "CreateRepo_Scalability10K_RDF4J"
Git repo exists
Running script with syntax: source prepareRunEnvironment.sh NUC8I7BEH RDF4JSUT CreateRepo_Scalability10K_RDF4J
tioannid@NUC8i7BEH:/data/geordfbench/scripts$ ./printRunEnvironment.sh
All SUTs
--------
Environment = NUC8I7BEH
EnvironmentBaseDir = /data
GeoRDFBenchScriptsDir = /data/geordfbench/scripts
GeoRDFBenchJSONLibDir = /data/geordfbench/json_defs
DatasetBaseDir = /data/Geographica2_Datasets
QuerysetBaseDir = /data/Geographica2_Datasets/QuerySets
ResultsBaseDir = /data
ResultsDirName = 313d935#_2025-05-15_RDF4JSUT_CreateRepo_Scalability10K_RDF4J
ActiveSUT = RDF4JSUT
ExperimentResultDir = /data/RDF4JSUT/313d935#_2025-05-15_RDF4JSUT_CreateRepo_Scalability10K_RDF4J
ExperimentDesc = 313d935#_2025-05-15_RDF4JSUT_CreateRepo_Scalability10K_RDF4J
CompletionReportDaemonIP = 192.168.1.44
CompletionReportDaemonPort = 3333
ScalabilityGenScriptName = /data/Geographica2_Datasets/Scalability/scalabilityDSGen.sh
ScalabilityGzipRefDSName = /data/Geographica2_Datasets/Scalability/scalability500MRefDS.nt.gz
SystemMemorySizeInGB = 32 GBs
JVM_Xmx = -Xmx24g
RDF4J SUT
---------
RDF4JRepoBaseDir = /data/RDF4J_4.3.15_Repos/server
EnableLuceneSail = false
RDF4JLuceneReposPrefix =
Version = 4.3.15
Sourcing the preparation script for repository generation has the added benefit that the user can use the environment variables in subsequent actions without the need to remember various long paths, as we see in the following sections.
tioannid@NUC8i7BEH:/data/geordfbench/scripts$ ls -lsa $ScalabilityGenScriptName
4 -rwxr-xr-x 1 tioannid tioannid 1406 Μαΐ 7 2023 /data/Geographica2_Datasets/Scalability/scalabilityDSGen.sh
tioannid@NUC8i7BEH:/data/geordfbench/scripts$ ls -lsa $ScalabilityGzipRefDSName
7745592 -rwxrwxrwx 1 tioannid tioannid 7931478121 Νοε 20 2020 /data/Geographica2_Datasets/Scalability/scalability500MRefDS.nt.gz
tioannid@NUC8i7BEH:/data/geordfbench/scripts$ ls -lsa /data/Geographica2_Datasets/Scalability
total 7745620
4 drwxrwxr-x 6 tioannid tioannid 4096 Απρ 26 15:53 .
4 drwxrwxr-x 11 tioannid tioannid 4096 Αυγ 9 2024 ..
4 drwxrwxrwx 2 tioannid tioannid 4096 Μαΐ 13 12:00 100K
4 drwxrwxrwx 2 tioannid tioannid 4096 Μαΐ 13 12:00 10K
4 drwxrwxrwx 2 tioannid tioannid 4096 Μαΐ 3 20:06 10M
4 drwxrwxrwx 2 tioannid tioannid 4096 Μαΐ 13 12:00 1M
7745592 -rwxrwxrwx 1 tioannid tioannid 7931478121 Νοε 20 2020 scalability500MRefDS.nt.gz
4 -rwxr-xr-x 1 tioannid tioannid 1406 Μαΐ 7 2023 scalabilityDSGen.sh
We can see that the compressed Scalability reference dataset and script are in place and that the 10K dataset has not been extracted yet. If the dataset have not been downloaded yet, the user can download both files in the links provided in this page, section Scalability Dataset Source Files.
tioannid@NUC8i7BEH:/data/geordfbench/scripts$ ls -lsa $RDF4JRepoBaseDir/repositories/
total 8
4 drwxrwxr-x 3 tioannid tioannid 4096 Μαΐ 8 2023 .
4 drwxrwxr-x 3 tioannid tioannid 4096 Μαΐ 6 2023 ..
We can see that there are no existing RDF4J repositories, yet, under the RDF4J base repo directory.
Since we used the preparation script earlier, we only need to specify one argument to the RDF4J wrapper repository generation script createAllRDF4JRepos.sh, "false', which specifies whether we would like to overwrite the repository in case it already exists. We also pipe the standard output and standard error descriptors to a log file.
tioannid@NUC8i7BEH:/data/geordfbench/scripts$ cd ../RDF4JSUT/scripts/CreateRepos/
tioannid@NUC8i7BEH:/data/geordfbench/RDF4JSUT/scripts/CreateRepos$ ./createAllRDF4JRepos.sh false 2>&1 | tee -a logCreateRepo_Scal10K_RDF4J.log
All of the following environment variables (geordfbench/scripts/prepareRunEnvironment.sh) are defined:
{DatasetBaseDir, RDF4JRepoBaseDir, JVM_Xmx, EnableLuceneSail, CompletionReportDaemonIP, CompletionReportDaemonPort, ScalabilityGenScriptName, ScalabilityGzipRefDSName}
Running script with syntax:
./createAllRDF4JRepos.sh false /data/Geographica2_Datasets /data/RDF4J_4.3.15_Repos/server -Xmx24g false 192.168.1.44 3333 /data/Geographica2_Datasets/Scalability/scalabilityDSGen.sh /data/Geographica2_Datasets/Scalability/scalability500MRefDS.nt.gz
Script start time: Πεμ 15 Μαΐ 2025 10:55:45 μμ EEST
Checking/Creating scalability 10K dataset ...
Scalability 10K dataset already exists
Generating scalability 10K repository ...
./createRDF4JRepo.sh /data/RDF4J_4.3.15_Repos/server scalability_10K false "spoc,posc" N-TRIPLES /data/Geographica2_Datasets/Scalability/10K -Xmx24g false "http://www.opengis.net/ont/geosparql#asWKT" 192.168.1.44 3333
CREATE_REPO_ARGS = createman "/data/RDF4J_4.3.15_Repos/server" "scalability_10K" "FALSE" "false" "spoc,posc" "http://www.opengis.net/ont/geosparql#asWKT"
LOAD_REPO_ARGS = dirloadman "/data/RDF4J_4.3.15_Repos/server" "scalability_10K" "N-TRIPLES" "/data/Geographica2_Datasets/Scalability/10K" true
0 [main] INFO RDF4JSystem - No LocalRepositoryManager instance present, creating a new one.
74 [main] INFO RDF4JSystem - Creating NativeStore base sail with spoc,posc indexes
210 [main] INFO RDF4JSystem - Creating new repository object for repo id = scalability_10K
428 [main] INFO RDF4JSystem - Initialing new repository object for repo id = scalability_10K
465 [main] INFO RepoUtil - RDF4J created with manager repo "/data/RDF4J_4.3.15_Repos/server/repositories/scalability_10K" in 68 msecs
466 [main] INFO RDF4JSystem - Closing connection...
467 [main] INFO RDF4JSystem - Repository closed.
0 [main] INFO RDF4JSystem - Loading file scalability_10K.nt ...
657 [main] INFO RDF4JSystem - Finished loading file scalability_10K.nt in 654 msecs
664 [main] INFO RepoUtil - RDF4J loaded with manager all files from "/data/Geographica2_Datasets/Scalability/10K" to repo "/data/RDF4J_4.3.15_Repos/server/repositories/scalability_10K" in 683 msecs
664 [main] INFO RDF4JSystem - Closing connection...
665 [main] INFO RDF4JSystem - Repository closed.
RDF4J repository "/data/RDF4J_4.3.15_Repos/server/repositories/scalability_10K" has size: 4MB
Script end time: Πεμ 15 Μαΐ 2025 10:55:49 μμ EEST
The RDF4J wrapper repository generation script, first checks if either all required script parameters have been passed or alternatively if all required environment variables have been set by the preparation script and informs the user about the actual script call that will be executed. This script call can, later on and if a user fills confortable with it, be used to run the RDF4J wrapper repository generation script with the desired ad-hoc arguments without having to first source the preparation script. Afterwards, for any dataset, the script checks if the dataset files are present, but specifically for Scalability datasets, the wrapper repository generation script will also create the dataset by extracting it from the reference dataset. In the listing above, we can see that since the /data/Geographica2_Datasets/Scalability/10K/scalability_10K.nt did not exist, the scalability generator script has been conveniently called and the required dataset file extracted. After that the main repository creation process begins, while informing the user about the actual arguments passed on to the RDF4J core repository generation script createRDF4JRepo.sh, which creates the repository and loads the data to it. Finally the repository location, name, size and loading times are reported.
tioannid@NUC8i7BEH:/data/geordfbench/RDF4JSUT/scripts/CreateRepos$ ls -lsa /data/Geographica2_Datasets/Scalability/10K
total 3720
4 drwxrwxrwx 2 tioannid tioannid 4096 Μαΐ 13 12:00 .
4 drwxrwxr-x 6 tioannid tioannid 4096 Απρ 26 15:53 ..
3712 -rw-rw-r-- 1 tioannid tioannid 3798364 Αυγ 9 2024 scalability_10K.nt
tioannid@NUC8i7BEH:/data/geordfbench/RDF4JSUT/scripts/CreateRepos$ ls -lsa $RDF4JRepoBaseDir/repositories/
total 12
4 drwxrwxr-x 3 tioannid tioannid 4096 Μαΐ 15 22:55 .
4 drwxrwxr-x 3 tioannid tioannid 4096 Μαΐ 15 22:55 ..
4 drwxrwxr-x 2 tioannid tioannid 4096 Μαΐ 15 22:55 scalability_10K
tioannid@NUC8i7BEH:/data/geordfbench/RDF4JSUT/scripts/CreateRepos$ ls $RDF4JRepoBaseDir/repositories/scalability_10K/
config.ttl namespaces.dat triples-posc.alloc triples.prop triples-spoc.dat values.dat values.id
contexts.dat nativerdf.ver triples-posc.dat triples-spoc.alloc txn-status values.hash
tioannid@NUC8i7BEH:/data/geordfbench/RDF4JSUT/scripts/CreateRepos$ ls -lsa *.log
4 -rw-rw-r-- 1 tioannid tioannid 2679 Μαΐ 15 22:55 logCreateRepo_Scal10K_RDF4J.log
The RDF4J workload experiment execution script runWLTestsForRDF4JSUT.sh is completely independent on the environment prepared earlier for the repository creation. However we can take advantage of it in order to shorten the length of long file paths.
tioannid@NUC8i7BEH:/data/geordfbench/RDF4JSUT/scripts/CreateRepos$ cd ../RunTests3/
tioannid@NUC8i7BEH:/data/geordfbench/RDF4JSUT/scripts/RunTests3$ DateTimeISO8601=`date --iso-8601='date'`
tioannid@NUC8i7BEH:/data/geordfbench/RDF4JSUT/scripts/RunTests3$ ./runWLTestsForRDF4JSUT.sh \
-Xmx24g \
-rbd ${RDF4JRepoBaseDir//"${EnvironmentBaseDir}/"} \
-expdesc ${DateTimeISO8601}_RDF4JSUT_RunWL_Scal10K \
-wl ${GeoRDFBenchJSONLibDir}/workloads/scalabilityFunc10K_WLoriginal_GOLD_STANDARD.json \
-h ${GeoRDFBenchJSONLibDir}/hosts/nuc8i7behHOSToriginal.json \
-rs ${GeoRDFBenchJSONLibDir}/reportspecs/simplereportspec_original.json \
-rpsr ${GeoRDFBenchJSONLibDir}/reportsources/nuc8i7behHOSToriginal.json 2>&1 | tee -a RunWLRDF4JExp_Scal10K.log
...(long listing, link below provides the RunWLRDF4JExp_Scal10K.log)...
Experiment run logs may be quite long, therefore the user can click the link below to view the details of the queryset execution.
tioannid@NUC8i7BEH:/data/geordfbench/RDF4JSUT/scripts/RunTests3$ ls -lsa *.log
76 -rw-rw-r-- 1 tioannid tioannid 71952 Μαΐ 15 23:25 RunWLRDF4JExp_Scal10K.log
Experiment results are stored by default in the file system.
tioannid@NUC8i7BEH:/data/geordfbench/RDF4JSUT/scripts/RunTests3$ ls -lsa /data/Results_Store/RDF4JSUT/
total 100
4 drwxrwxr-x 25 tioannid tioannid 4096 Μαΐ 15 23:33 .
4 drwxrwxr-x 8 tioannid tioannid 4096 Απρ 27 19:50 ..
...
4 drwxrwxr-x 3 tioannid tioannid 4096 Μαΐ 15 23:33 2025-05-15_RDF4JSUT_RunWL_Scal10K
tioannid@NUC8i7BEH:/data/geordfbench/RDF4JSUT/scripts/RunTests3$ tree /data/Results_Store/RDF4JSUT/2025-05-15_RDF4JSUT_RunWL_Scal10K/
/data/Results_Store/RDF4JSUT/2025-05-15_RDF4JSUT_RunWL_Scal10K/
└── Scalability
└── 10K
└── RDF4JSUT-ExperimentWorkload
├── 00-SC1_Geometries_Intersects_GivenPolygon-cold
├── 00-SC1_Geometries_Intersects_GivenPolygon-cold-long
├── 00-SC1_Geometries_Intersects_GivenPolygon-warm
├── 00-SC1_Geometries_Intersects_GivenPolygon-warm-long
├── 01-SC2_Intensive_Geometries_Intersect_Geometries-cold
├── 01-SC2_Intensive_Geometries_Intersect_Geometries-cold-long
├── 01-SC2_Intensive_Geometries_Intersect_Geometries-warm
├── 01-SC2_Intensive_Geometries_Intersect_Geometries-warm-long
├── 02-SC3_Relaxed_Geometries_Intersect_Geometries-cold
├── 02-SC3_Relaxed_Geometries_Intersect_Geometries-cold-long
├── 02-SC3_Relaxed_Geometries_Intersect_Geometries-warm
└── 02-SC3_Relaxed_Geometries_Intersect_Geometries-warm-long
3 directories, 12 files
For each query and execution type (warm, cold) there are two files, a short and a long version. The long version has 4 columns (noOfResults, evaluationTime, scanTime, totalTime) and one row for each execution iteration performed. The short version has 2 columns (noOfResults, totalTime) and only one row which represents the average or median totalTime of the execution iterations from the long version. All times are in nano seconds.
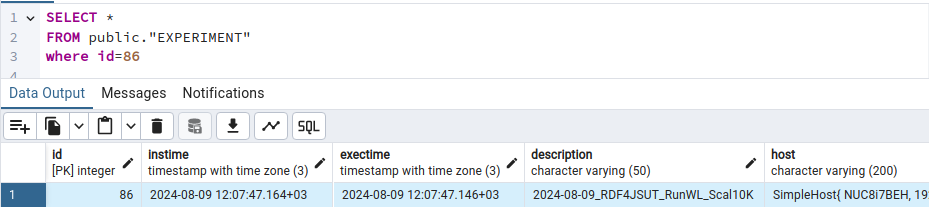
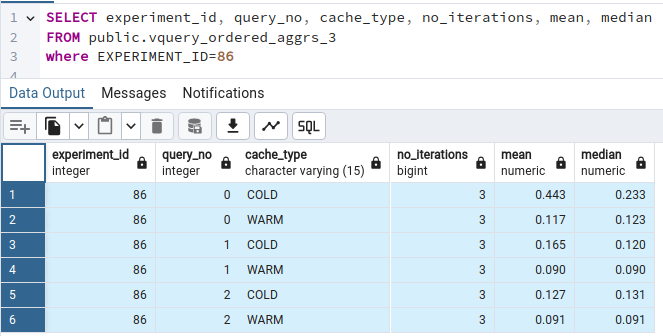
Experiment results are also stored in a custom location, a PostgreSQL database. The details of this report sink can be seen above in the link of section Run the Scalability-10K Workload Experiment with RDF4J. Each experiment details are recorded, with a unique ID, in a row of the EXPERIMENTS table. Each query execution iteration details are in a similar manner recorded in the QUERYEXECUTIONS table. A set of views can provide aggregation for the totalTime and calculation of the Average and Median value of totalTime for each query and execution type (warm, cold). All times are in milli seconds.
(exports from PgAdmin v4)
=== EXPERIMENT ENTRY ========
"id","instime","exectime","description","host","os","sut","queryset","dataset","executionspec","reportspec","type"
79,"2025-05-15 23:30:47.874+03","2025-05-15 23:30:47.861+03","2025-05-15_RDF4JSUT_RunWL_Scal10K","SimpleHost{ NUC8i7BEH, 192.168.1.44, 32GB, UbuntuJammyOS{ Ubuntu-jammy } }","UbuntuJammyOS{ Ubuntu-jammy }","RDF4JSUT","scalabilityFunc","scalability_10K","SimpleES{ COLD=3, WARM=3, action=RUN, maxduration=604800 secs, repmaxduration=86400 secs, func=QUERY_MEDIAN }","SimpleReportSpec","ScalabilityFunc"
=== AGGREGATE DATA ===========
"experiment_id" "query_no" "cache_type" "no_iterations" "mean" "median"
79 0 "COLD" 3 0.381 0.326
79 0 "WARM" 3 0.123 0.119
79 1 "COLD" 3 0.239 0.191
79 1 "WARM" 3 0.121 0.121
79 2 "COLD" 3 0.172 0.173
79 2 "WARM" 3 0.127 0.127
In the figures below we can see the actual snapshots from the PgAdmin v4 interface.