By Theofilos Ioannidis (tioannid [at] di [dot] uoa [dot] gr), created on , last updated on
The purpose of GeoRDFBench Framework is to assist and streamline the researcher's work on the field of benchmarking geospatial semantic stores. The Runtime API models all identified benchmark components, groups them, forms specialization hierarchies of classes and interfaces for them, and supports serialization to and deserialization from external JSON specification files. It also creates a JSON Benchmark Specification Library and initializes it with the serialized component instances of the Geographica 2 [2] benchmark. The increased reusability of these JSON benchmark specifications, allows focus to stay on the research task ahead while minimizing the time from idea conception to benchmark results and usefull conclusions. Geospatial RDF store architecture and behaviour is unified by generalizing the repository and connection functionalities of the three most common RDF framework APIs used by RDF stores: OpenRDF Sesame [4], Eclipse RDF4J and Apache Jena. At the same time it allows automatic system-dependent query namespace prefix management and customized query rewriting when non GeoSPARQL spatial vocabularies are used. GeoRDFBench goes even further and models the application and database server modules present in some stores and automates their life-cycle management during experiment execution. The framework comes with several geospatial RDF Stores, implemented as separate Runtime-dependent modules. Each module contains scripts for repository generation and experiment execution, which allows for a quick start on using the platform. RDF modules include: RDF4J, GraphDB, Stardog, Strabon, OpenLink Virtuoso and Jena GeoSPARQL.
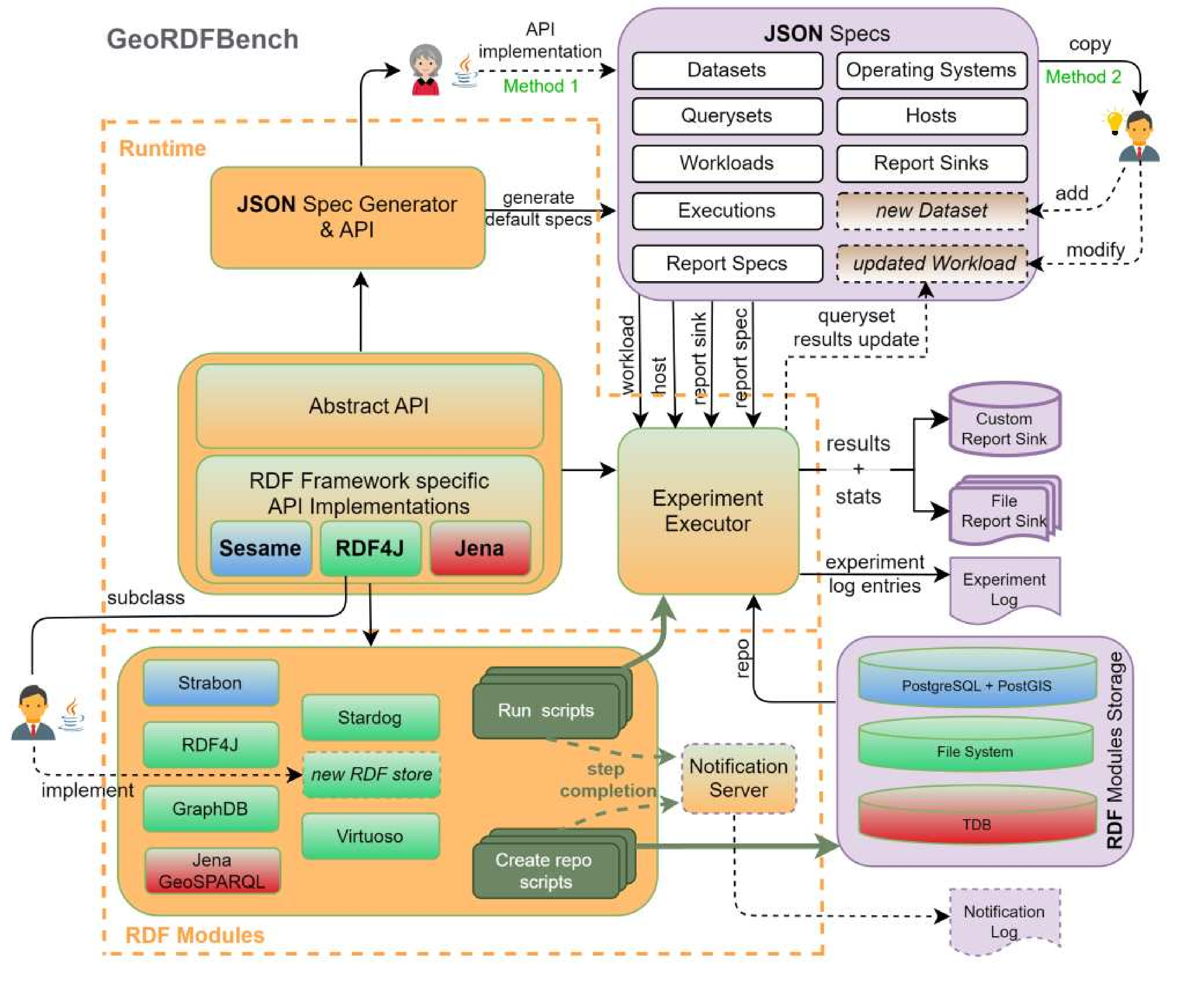
The high level architecture of the framework is depicted below:
The system consists of two main parts: the Runtime and the RDF Modules, depicted inside the dashed border.
The Runtime is the engine and fabric of the framework and it is responsible for generating default JSON benchmark specifications and executing experiments initiated by the RDF modules' run scripts. The Abstract API abstracts the properties, functionalities and interactions of the benchmark components and the SUTs both of which are conceptually depicted in the corresponding Enhanced-ER (EER) diagrams that follow.
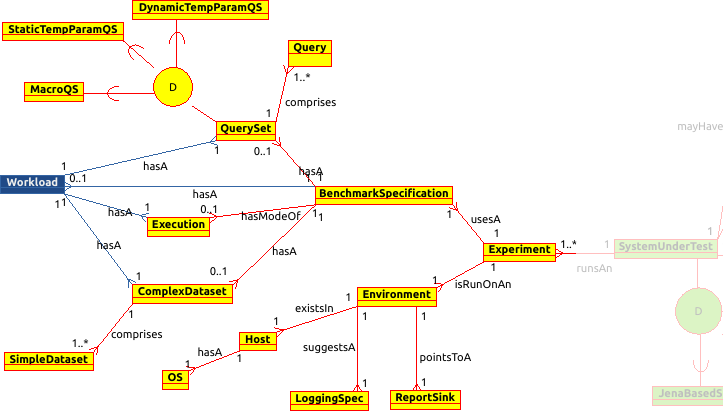
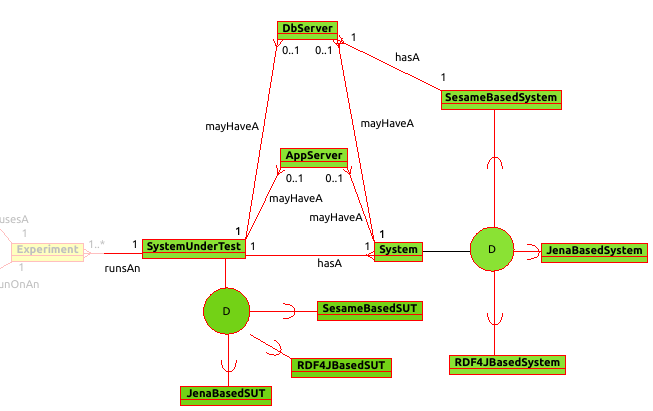
The RDF Modules is where pre-implemented and newly implemented RDF stores reside that can participate in experiments. Stores use their repository creation script to create repositories and import data to them. Each store's experiment run script initiates a benchmark experiment and eventually invokes the runtime's Experiment Executor component passing all required inputs which include, among others: the RDF store repository, the benchmark workload (dataset + queryset + execution specification), the host where the experiment is conducted on, the report sink where experiment results and statistics will be stored and the logging or report specs. Both types of scripts send progress messages to the optionally enabled, remote or local, Notification Server which logs them and can serve as a useful non-intrusive (remote server) monitoring tool for the researcher.
For a more in-depth presentation of the framework, please consult the paper "The GeoRDFBench Framework: Geospatial Semantic Benchmarking Simplified" [1].